...
- First, to identify the samples that are contaminated we will be using the haplocheck_results file. For that, check the column B (Contaminated Status) and verify if there is any sample indicating YES. If , you will need to copy the Sample IDs (column A: Sample) and paste in a new excel file. Name your file as samples_to_remove and save it as txt format (see the image Figure 1 below as an example).
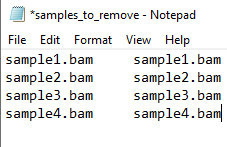
Figure 1 - samples_to_remove.txt file example.
#NOTE: The samples_to_remove.txt file should have two columns and no header. Both columns have the same information (Sample IDs). This file is going to be used in further steps. If you want, you can already upload this file into your work directory in the SCC cluster.
- Continue the next steps using the Merged.txt
...
- file.
- First, call the first excel tab as Merged_raw_data.
- Second, create a 2nd tab and call it as Merged_nocont. Copy the entire data from the raw results (1st tab - Merged_raw_data) and paste it into the 2nd tab. Using the Sample IDs from the samples_to_remove.txt file you will identify the variants from the each one of the contaminated samples and manually remove their respective rows on the Merged_nocont tab.
#NOTE: Check out at the end of this section an example of how the excel file was organized in different sheets based on the QC steps (Figure
...
2).
5. Homoplasmic and common variants filtering using PLINK in the SCC cluster
...